

Grok 4 Benchmarks are making headlines following its delayed July 9 livestream debut, where Elon Musk and the xAI team unveiled the model as a leap into what Musk dubbed the era of “Big Bang Intelligence.”
Packed with multimodal capabilities, faster reasoning, and a redesigned interface, Grok 4 is being measured not just by hype—but by its standout performance across ARC-AGI, Vending-Bench, and HLE.
ARC-AGI-2: Reasoning Power vs. Cost Efficiency
The ARC-AGI-2 leaderboard is a critical benchmark that assesses models on complex reasoning tasks while accounting for cost-efficiency. The x-axis shows cost per task (log scale), and the y-axis shows score percentage—how well the model performs.
- Grok 4 (Thinking) sits at the top-right corner, delivering ~18% accuracy, clearly ahead of Claude Opus 4 (~10%) and GPT-4.5 or o3 variants.
- While Grok 4 is more expensive per task, it leads in raw performance—a compelling choice when task accuracy is mission-critical.
- Grok 3 Mini and other Grok models (non-Thinking) offer low-cost alternatives with reduced performance.
Key Takeaway:
Grok 4 Thinking leads the pack in reasoning, offering unmatched performance even with higher costs, showing its suitability for complex, high-stakes tasks.
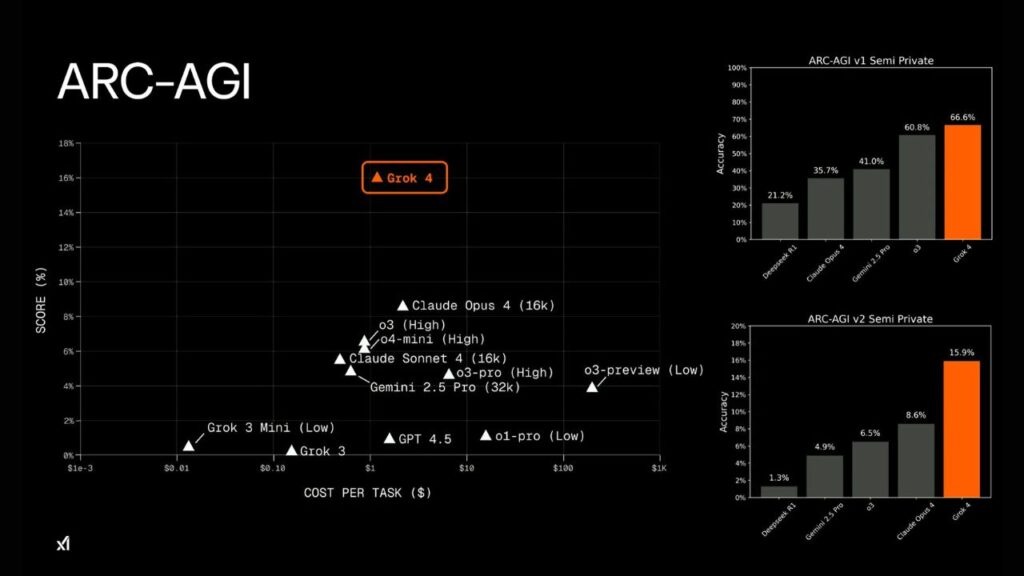
Vending-Bench: Economic Reasoning in Simulated Markets
The Vending-Bench simulates a dynamic market where agents (models) compete to sell items and maximize net worth over time. It evaluates economic reasoning and business strategy.
- Grok 4 achieved a stunning mean net worth of $4694.15, far ahead of Claude Opus 4 ($2077.41) and even human participants ($844.05).
- It also sold the highest number of units on average: 4569, indicating strong demand-generation capabilities.
- The net worth over time curve (right) shows Grok 4 outpacing all other models in sustained performance.
Key Takeaway:
In business strategy and decision-making under pressure, Grok 4 behaves like a top-tier CEO—combining intelligence, foresight, and execution.
Scaling HLE with Tools: Grok’s Tool-Use Advantage
This chart compares models trained with and without tool usage on the HLE (High-Level Evaluation) benchmark. It reveals how tool integration boosts general-purpose reasoning.
- Grok 4’s performance (with tools) hits 41%, surpassing all prior SOTA (state-of-the-art) models.
- The jump from 26.9% (no tools) to 41% (with tools) shows a 14.1% gain, underlining Grok 4’s exceptional tool-use adaptation.
Key Takeaway:
Grok 4 not only scales well with compute but amplifies its capabilities through tool use, showing promise for real-world integration with external systems.
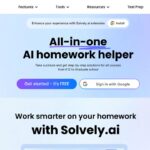
ARC-AGI (v1 & v2): General Intelligence Under the Microscope
ARC-AGI v1 (Semi-Private):
- Grok 4 scored 66.6%, outperforming Claude Opus 4 (35.7%), Gemini 2.5 Pro (41%), and o3 (60.8%).
ARC-AGI v2 (Semi-Private):
- Grok 4 achieved 15.9%, a significant lead over Claude Opus 4 (8.6%) and Gemini 2.5 Pro (6.5%).
On the cost-performance graph (left), Grok 4 remains dominant even in private evaluation settings.
Key Takeaway:
Grok 4 sets new records on both ARC-AGI versions, proving its robustness across evolving reasoning benchmarks.
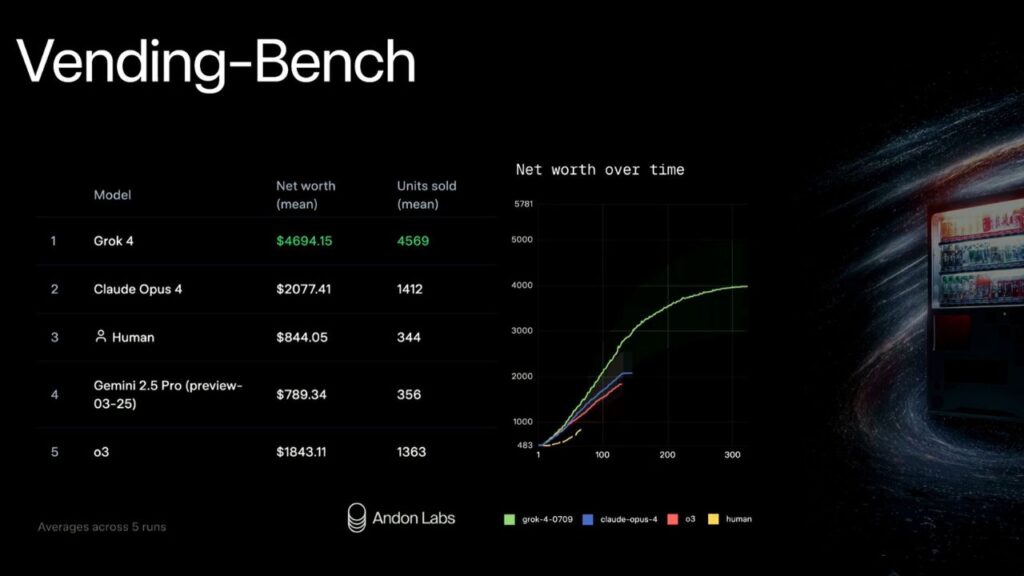
Humanity’s Last Exam (HLE): Full-Stack Intelligence
This final benchmark measures text-only and tool-augmented performance on a broad exam representing tasks across humanity’s cognitive spectrum.
- Grok 4 (no tools): 25.4%
- Grok 4 (with tools): 38.6%
- Grok 4 Heavy (with tools): 44.4%
These numbers not only surpass every other model, but also show that tool use gives Grok models a decisive edge.
Key Takeaway:
Grok 4—with and without tools—is leading “Humanity’s Last Exam”, a symbolic indicator of full-spectrum general intelligence.
Final Thoughts
Grok 4 isn’t just another large language model—it’s a versatile, high-performing, and economically intelligent agent. Across reasoning, business simulation, tool-use adaptability, and real-world testing, Grok 4 leads or outperforms in virtually every benchmark.
Why This Matters:
- Enterprises can depend on Grok 4 for mission-critical reasoning and strategy.
- Developers and researchers have access to a model that scales with tools, offering massive potential for integration.
- From exams to economics, Grok 4 signals a powerful shift in how AGI systems are being evaluated—and deployed.